CS 6362 - Advanced Machine Learning
Assignment 2
In this assignment you will implement a Gaussian process regression model. Please go here for data, and starter code.
The provided dataset is a scattered set of 2D points, each containing a sample of a density field that resulted from a Rayleigh-Taylor instability simulation. The objective of the assignment is to build a Gaussian process regression model given these data points, so that we can reconstruct the remainder of the field. This is commonly known as Kriging in the literature, see e.g. this link.
There are two main parts of this assignment:
Gaussian Process Construction (45 points)
Here you will implement the key pieces of a Gaussian process:
- The kernel function. Here you should implement a squared-exponential kernel. You should use 2 hyperparameters for the kernel: the noise variance, and the length scale. The length scale will be shared between the x- and y-coordinates of the 2D domain, for simplicity. (15 points)
- Given training data, compute the posterior mean and posterior covariance. (15 points)
- A method for sampling the posterior distribution. This will allow us to take random draws of the 2D scalar field. Please see Sec. A.3 within (Rasmussen & Williams) for details on how to draw samples from a multivariate normal. (15 points)
Model Selection (45 points)
You should implement a cross-validation scheme for finding kernel hyperparameters. Namely, you should implement k-fold cross-validation, with k being an adjustable parameter, and use the folds to perform a 2D grid search over the aforementioned hyperparameters (noise variance and length scale). Specifically, your code needs to support:
- Generation of folds, given the training data. (15 points)
- Iterate through all combinations of hyperparameters, for each setting of hyperparameters build and evaluate a model across all folds, and last, take the hyperparameter with best results. You should use mean-squared error for evaluation. (30 points)
Model Evaluation (10 points)
The result of cross-validation should provide us with a setting of hyperparameters, with which we can construct a Gaussian process using all of the training data. You should be able to take the test dataset provided and run this model, producing an output.
Please see the driver.py script for further details.
Separately, I will evaluate your model’s prediction on the ground-truth. The performance of your model will determine the amount of credit you receive on this part of the assignment.
Within here, you should also be able to uncomment the code at the bottom, and draw samples (e.g. images) from your Gaussian process model. This is a decent way to test your model, absent of ground-truth. You should see something like the following:
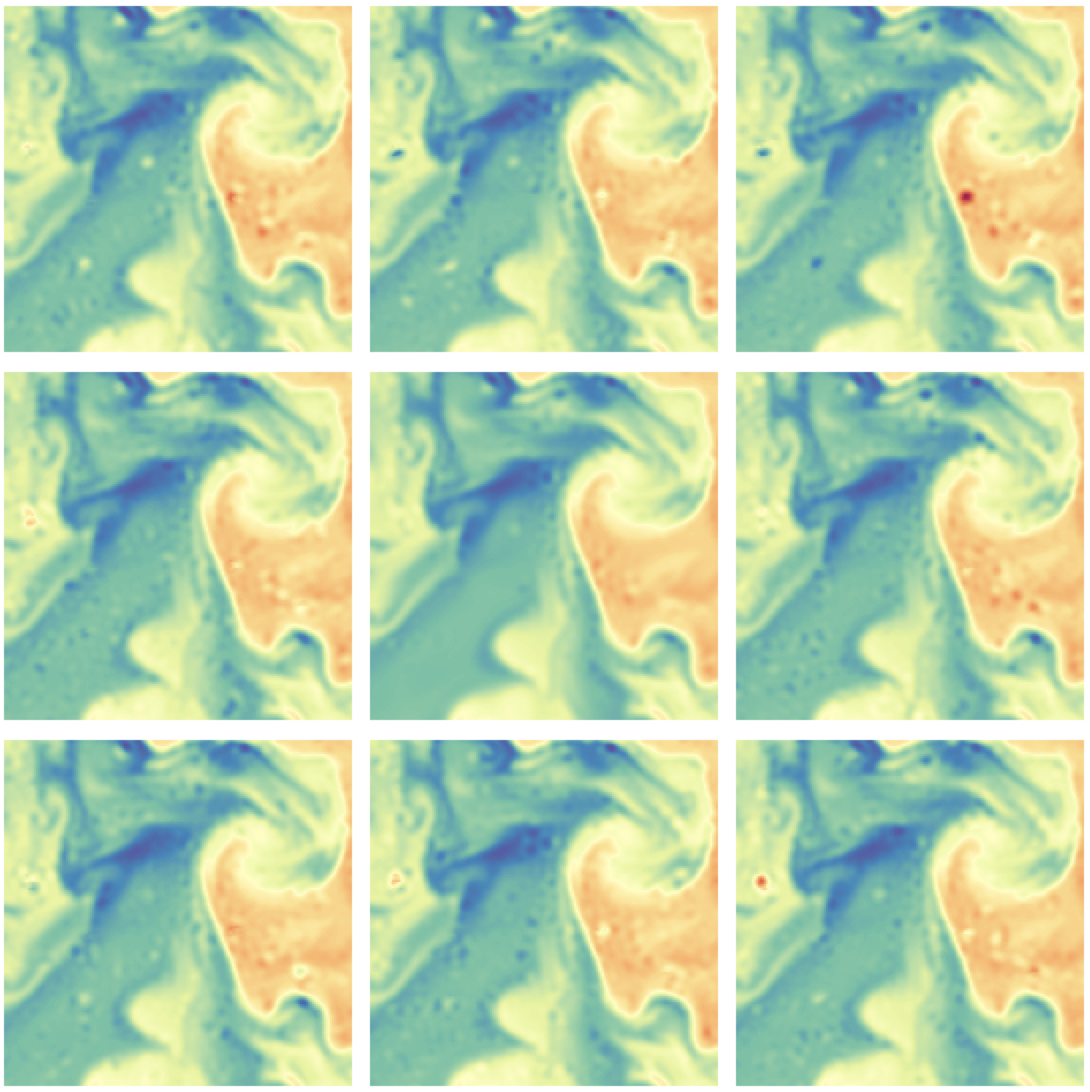
In the above, the center image is the posterior mean, while the remaining images are random draws from the posterior distribution.